
Excellent Papers for 2011
March 22, 2012
Posted by Corinna Cortes and Alfred Spector, Google Research
Quick links
UPDATE: Added Theo Vassilakis as an author for "Dremel: Interactive Analysis of Web-Scale Datasets"
Googlers across the company actively engage with the scientific community by publishing technical papers, contributing open-source packages, working on standards, introducing new APIs and tools, giving talks and presentations, participating in ongoing technical debates, and much more. Our publications offer technical and algorithmic advances, feature aspects we learn as we develop novel products and services, and shed light on some of the technical challenges we face at Google.
In an effort to highlight some of our work, we periodically select a number of publications to be featured on this blog. We first posted a set of papers on this blog in mid-2010 and subsequently discussed them in more detail in the following blog postings. In a second round, we highlighted new noteworthy papers from the later half of 2010. This time we honor the influential papers authored or co-authored by Googlers covering all of 2011 -- covering roughly 10% of our total publications. It’s tough choosing, so we may have left out some important papers. So, do see the publications list to review the complete group.
In the coming weeks we will be offering a more in-depth look at these publications, but here are some summaries:
Audio processing
“Cascades of two-pole–two-zero asymmetric resonators are good models of peripheral auditory function”, Richard F. Lyon, Journal of the Acoustical Society of America, vol. 130 (2011), pp. 3893-3904.
Lyon's long title summarizes a result that he has been working toward over many years of modeling sound processing in the inner ear. This nonlinear cochlear model is shown to be "good" with respect to psychophysical data on masking, physiological data on mechanical and neural response, and computational efficiency. These properties derive from the close connection between wave propagation and filter cascades. This filter-cascade model of the ear is used as an efficient sound processor for several machine hearing projects at Google.
Electronic Commerce and Algorithms
“Online Vertex-Weighted Bipartite Matching and Single-bid Budgeted Allocations”, Gagan Aggarwal, Gagan Goel, Chinmay Karande, Aranyak Mehta, SODA 2011.
The authors introduce an elegant and powerful algorithmic technique to the area of online ad allocation and matching: a hybrid of random perturbations and greedy choice to make decisions on the fly. Their technique sheds new light on classic matching algorithms, and can be used, for example, to pick one among a set of relevant ads, without knowing in advance the demand for ad slots on future web page views.
“Milgram-routing in social networks”, Silvio Lattanzi, Alessandro Panconesi, D. Sivakumar, Proceedings of the 20th International Conference on World Wide Web, WWW 2011, pp. 725-734.
Milgram’s "six-degrees-of-separation experiment" and the fascinating small world hypothesis that follows from it, have generated a lot of interesting research in recent years. In this landmark experiment, Milgram showed that people unknown to each other are often connected by surprisingly short chains of acquaintances. In the paper we prove theoretically and experimentally how a recent model of social networks, "Affiliation Networks", offers an explanation to this phenomena and inspires interesting technique for local routing within social networks.
“Non-Price Equilibria in Markets of Discrete Goods”, Avinatan Hassidim, Haim Kaplan, Yishay Mansour, Noam Nisan, EC, 2011.
We present a correspondence between markets of indivisible items, and a family of auction based n player games. We show that a market has a price based (Walrasian) equilibrium if and only if the corresponding game has a pure Nash equilibrium. We then turn to markets which do not have a Walrasian equilibrium (which is the interesting case), and study properties of the mixed Nash equilibria of the corresponding games.
HCI
“From Basecamp to Summit: Scaling Field Research Across 9 Locations”, Jens Riegelsberger, Audrey Yang, Konstantin Samoylov, Elizabeth Nunge, Molly Stevens, Patrick Larvie, CHI 2011 Extended Abstracts.
The paper reports on our experience with a basecamp research hub to coordinate logistics and ongoing real-time analysis with research teams in the field. We also reflect on the implications for the meaning of research in a corporate context, where much of the value may be less in a final report, but more in the curated impressions and memories our colleagues take away from the the research trip.
“User-Defined Motion Gestures for Mobile Interaction”, Jaime Ruiz, Yang Li, Edward Lank, CHI 2011: ACM Conference on Human Factors in Computing Systems, pp. 197-206.
Modern smartphones contain sophisticated sensors that can detect rich motion gestures — deliberate movements of the device by end-users to invoke commands. However, little is known about best-practices in motion gesture design for the mobile computing paradigm. We systematically studied the design space of motion gestures via a guessability study that elicits end-user motion gestures to invoke commands on a smartphone device. The study revealed consensus among our participants on parameters of movement and on mappings of motion gestures onto commands, by which we developed a taxonomy for motion gestures and compiled an end-user inspired motion gesture set. The work lays the foundation of motion gesture design—a new dimension for mobile interaction.
Information Retrieval
“Reputation Systems for Open Collaboration”, B.T. Adler, L. de Alfaro, A. Kulshreshtha , I. Pye, Communications of the ACM, vol. 54 No. 8 (2011), pp. 81-87.
This paper describes content based reputation algorithms, that rely on automated content analysis to derive user and content reputation, and their applications for Wikipedia and google Maps. The Wikipedia reputation system WikiTrust relies on a chronological analysis of user contributions to articles, metering positive or negative increments of reputation whenever new contributions are made. The Google Maps system Crowdsensus compares the information provided by users on map business listings and computes both a likely reconstruction of the correct listing and a reputation value for each user. Algorithmic-based user incentives ensure the trustworthiness of evaluations of Wikipedia entries and Google Maps business information.
Machine Learning and Data Mining
“Domain adaptation in regression”, Corinna Cortes, Mehryar Mohri, Proceedings of The 22nd International Conference on Algorithmic Learning Theory, ALT 2011.
Domain adaptation is one of the most important and challenging problems in machine learning. This paper presents a series of theoretical guarantees for domain adaptation in regression, gives an adaptation algorithm based on that theory that can be cast as a semi-definite programming problem, derives an efficient solution for that problem by using results from smooth optimization, shows that the solution can scale to relatively large data sets, and reports extensive empirical results demonstrating the benefits of this new adaptation algorithm.
“On the necessity of irrelevant variables”, David P. Helmbold, Philip M. Long, ICML, 2011
Relevant variables sometimes do much more good than irrelevant variables do harm, so that it is possible to learn a very accurate classifier using predominantly irrelevant variables. We show that this holds given an assumption that formalizes the intuitive idea that the variables are non-redundant. For problems like this it can be advantageous to add many additional variables, even if only a small fraction of them are relevant.
“Online Learning in the Manifold of Low-Rank Matrices”, Gal Chechik, Daphna Weinshall, Uri Shalit, Neural Information Processing Systems (NIPS 23), 2011, pp. 2128-2136.
Learning measures of similarity from examples of similar and dissimilar pairs is a problem that is hard to scale. LORETA uses retractions, an operator from matrix optimization, to learn low-rank similarity matrices efficiently. This allows to learn similarities between objects like images or texts when represented using many more features than possible before.
Machine Translation
“Training a Parser for Machine Translation Reordering”, Jason Katz-Brown, Slav Petrov, Ryan McDonald, Franz Och, David Talbot, Hiroshi Ichikawa, Masakazu Seno, Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP '11).
Machine translation systems often need to understand the syntactic structure of a sentence to translate it correctly. Traditionally, syntactic parsers are evaluated as standalone systems against reference data created by linguists. Instead, we show how to train a parser to optimize reordering accuracy in a machine translation system, resulting in measurable improvements in translation quality over a more traditionally trained parser.
“Watermarking the Outputs of Structured Prediction with an application in Statistical Machine Translation”, Ashish Venugopal, Jakob Uszkoreit, David Talbot, Franz Och, Juri Ganitkevitch, Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP).
We propose a general method to watermark and probabilistically identify the structured results of machine learning algorithms with an application in statistical machine translation. Our approach does not rely on controlling or even knowing the inputs to the algorithm and provides probabilistic guarantees on the ability to identify collections of results from one’s own algorithm, while being robust to limited editing operations.
“Inducing Sentence Structure from Parallel Corpora for Reordering”, John DeNero, Jakob Uszkoreit, Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Automatically discovering the full range of linguistic rules that govern the correct use of language is an appealing goal, but extremely challenging. Our paper describes a targeted method for discovering only those aspects of linguistic syntax necessary to explain how two different languages differ in their word ordering. By focusing on word order, we demonstrate an effective and practical application of unsupervised grammar induction that improves a Japanese to English machine translation system.
Multimedia and Computer Vision
“Kernelized Structural SVM Learning for Supervised Object Segmentation”, Luca Bertelli, Tianli Yu, Diem Vu, Burak Gokturk,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition 2011.
The paper proposes a principled way for computers to learn how to segment the foreground from the background of an image given a set of training examples. The technology is build upon a specially designed nonlinear segmentation kernel under the recently proposed structured SVM learning framework.
“Auto-Directed Video Stabilization with Robust L1 Optimal Camera Paths”, Matthias Grundmann, Vivek Kwatra, Irfan Essa, IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011).
Casually shot videos captured by handheld or mobile cameras suffer from significant amount of shake. Existing in-camera stabilization methods dampen high-frequency jitter but do not suppress low-frequency movements and bounces, such as those observed in videos captured by a walking person. On the other hand, most professionally shot videos usually consist of carefully designed camera configurations, using specialized equipment such as tripods or camera dollies, and employ ease-in and ease-out for transitions. Our stabilization technique automatically converts casual shaky footage into more pleasant and professional looking videos by mimicking these cinematographic principles. The original, shaky camera path is divided into a set of segments, each approximated by either constant, linear or parabolic motion, using an algorithm based on robust L1 optimization. The stabilizer has been part of the YouTube Editor (youtube.com/editor) since March 2011.
“The Power of Comparative Reasoning”, Jay Yagnik, Dennis Strelow, David Ross, Ruei-Sung Lin, International Conference on Computer Vision (2011).
The paper describes a theory derived vector space transform that converts vectors into sparse binary vectors such that Euclidean space operations on the sparse binary vectors imply rank space operations in the original vector space. The transform a) does not need any data-driven supervised/unsupervised learning b) can be computed from polynomial expansions of the input space in linear time (in the degree of the polynomial) and c) can be implemented in 10-lines of code. We show competitive results on similarity search and sparse coding (for classification) tasks.
NLP
“Unsupervised Part-of-Speech Tagging with Bilingual Graph-Based Projections”, Dipanjan Das, Slav Petrov, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL '11), 2011, Best Paper Award.
We would like to have natural language processing systems for all languages, but obtaining labeled data for all languages and tasks is unrealistic and expensive. We present an approach which leverages existing resources in one language (for example English) to induce part-of-speech taggers for languages without any labeled training data. We use graph-based label propagation for cross-lingual knowledge transfer and use the projected labels as features in a hidden Markov model trained with the Expectation Maximization algorithm.
Networks
“TCP Fast Open”, Sivasankar Radhakrishnan, Yuchung Cheng, Jerry Chu, Arvind Jain, Barath Raghavan, Proceedings of the 7th International Conference on emerging Networking EXperiments and Technologies (CoNEXT), 2011.
TCP Fast Open enables data exchange during TCP’s initial handshake. It decreases application network latency by one full round-trip time, a significant speedup for today's short Web transfers. Our experiments on popular websites show that Fast Open reduces the whole-page load time over 10% on average, and in some cases up to 40%.
“Proportional Rate Reduction for TCP”, Nandita Dukkipati, Matt Mathis, Yuchung Cheng, Monia Ghobadi, Proceedings of the 11th ACM SIGCOMM Conference on Internet Measurement 2011, Berlin, Germany - November 2-4, 2011.
Packet losses increase latency of Web transfers and negatively impact user experience. Proportional rate reduction (PRR) is designed to recover from losses quickly, smoothly and accurately by pacing out retransmissions across received ACKs during TCP’s fast recovery. Experiments on Google Web and YouTube servers in U.S. and India demonstrate that PRR reduces the TCP latency of connections experiencing losses by 3-10% depending on response size.
Security and Privacy
“Automated Analysis of Security-Critical JavaScript APIs”, Ankur Taly, Úlfar Erlingsson, John C. Mitchell, Mark S. Miller, Jasvir Nagra, IEEE Symposium on Security & Privacy (SP), 2011.
As software is increasingly written in high-level, type-safe languages, attackers have fewer means to subvert system fundamentals, and attacks are more likely to exploit errors and vulnerabilities in application-level logic. This paper describes a generic, practical defense against such attacks, which can protect critical application resources even when those resources are partially exposed to attackers via software interfaces. In the context of carefully-crafted fragments of JavaScript, the paper applies formal methods and semantics to prove that these defenses can provide complete, non-circumventable mediation of resource access; the paper also shows how an implementation of the techniques can establish the properties of widely-used software, and find previously-unknown bugs.
“App Isolation: Get the Security of Multiple Browsers with Just One”, Eric Y. Chen, Jason Bau, Charles Reis, Adam Barth, Collin Jackson, 18th ACM Conference on Computer and Communications Security, 2011.
We find that anecdotal advice to use a separate web browser for sites like your bank is indeed effective at defeating most cross-origin web attacks. We also prove that a single web browser can provide the same key properties, for sites that fit within the compatibility constraints.
Speech
“Improving the speed of neural networks on CPUs”, Vincent Vanhoucke, Andrew Senior, Mark Z. Mao, Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011.
As deep neural networks become state-of-the-art in real-time machine learning applications such as speech recognition, computational complexity is fast becoming a limiting factor in their adoption. We show how to best leverage modern CPU architectures to significantly speed-up their inference.
“Bayesian Language Model Interpolation for Mobile Speech Input”, Cyril Allauzen, Michael Riley, Interspeech 2011.
Voice recognition on the Android platform must contend with many possible target domains - e.g. search, maps, SMS. For each of these, a domain-specific language model was built by linearly interpolating several n-gram LMs from a common set of Google corpora. The current work has found a way to efficiently compute a single n-gram language model with accuracy very close to the domain-specific LMs but with considerably less complexity at recognition time.
Statistics
“Large-Scale Parallel Statistical Forecasting Computations in R”, Murray Stokely, Farzan Rohani, Eric Tassone, JSM Proceedings, Section on Physical and Engineering Sciences, 2011.
This paper describes the implementation of a framework for utilizing distributed computational infrastructure from within the R interactive statistical computing environment, with applications to timeseries forecasting. This system is widely used by the statistical analyst community at Google for data analysis on very large data sets.
Structured Data
“Dremel: Interactive Analysis of Web-Scale Datasets”, Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Communications of the ACM, vol. 54 (2011), pp. 114-123.
Dremel is a scalable, interactive ad-hoc query system. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds. Besides continued growth internally to Google, Dremel now also backs an increasing number of external customers including BigQuery and UIs such as AdExchange front-end.
“Representative Skylines using Threshold-based Preference Distributions”, Atish Das Sarma, Ashwin Lall, Danupon Nanongkai, Richard J. Lipton, Jim Xu, International Conference on Data Engineering (ICDE), 2011.
The paper adopts principled approach towards representative skylines and formalizes the problem of displaying k tuples such that the probability that a random user clicks on one of them is maximized. This requires mathematically modeling (a) the likelihood with which a user is interested in a tuple, as well as (b) how one negotiates the lack of knowledge of an explicit set of users. This work presents theoretical and experimental results showing that the suggested algorithm significantly outperforms previously suggested approaches.
“Hyper-local, directions-based ranking of places”, Petros Venetis, Hector Gonzalez, Alon Y. Halevy, Christian S. Jensen, PVLDB, vol. 4(5) (2011), pp. 290-30.
Click through information is one of the strongest signals we have for ranking web pages. We propose an equivalent signal for raking real world places: The number of times that people ask for precise directions to the address of the place. We show that this signal is competitive in quality with human reviews while being much cheaper to collect, we also show that the signal can be incorporated efficiently into a location search system.
Systems
“Power Management of Online Data-Intensive Services”, David Meisner, Christopher M. Sadler, Luiz André Barroso, Wolf-Dietrich Weber, Thomas F. Wenisch, Proceedings of the 38th ACM International Symposium on Computer Architecture, 2011.
Compute and data intensive Web services (such as Search) are a notoriously hard target for energy savings techniques. This article characterizes the statistical hardware activity behavior of servers running Web search and discusses the potential opportunities of existing and proposed energy savings techniques.
“The Impact of Memory Subsystem Resource Sharing on Datacenter Applications”, Lingjia Tang, Jason Mars, Neil Vachharajani, Robert Hundt, Mary-Lou Soffa, ISCA, 2011.
In this work, the authors expose key characteristics of an emerging class of Google-style workloads and show how to enhance system software to take advantage of these characteristics to improve efficiency in data centers. The authors find that across datacenter applications, there is both a sizable benefit and a potential degradation from improperly sharing micro-architectural resources on a single machine (such as on-chip caches and bandwidth to memory). The impact of co-locating threads from multiple applications with diverse memory behavior changes the optimal mapping of thread to cores for each application. By employing an adaptive thread-to-core mapper, the authors improved the performance of the datacenter applications by up to 22% over status quo thread-to-core mapping, achieving performance within 3% of optimal.
“Language-Independent Sandboxing of Just-In-Time Compilation and Self-Modifying Code”, Jason Ansel, Petr Marchenko, Úlfar Erlingsson, Elijah Taylor, Brad Chen, Derek Schuff, David Sehr, Cliff L. Biffle, Bennet S. Yee, ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2011.
Since its introduction in the early 90's, Software Fault Isolation, or SFI, has been a static code technique, commonly perceived as incompatible with dynamic libraries, runtime code generation, and other dynamic code. This paper describes how to address this limitation and explains how the SFI techniques in Google Native Client were extended to support modern language implementations based on just-in-time code generation and runtime instrumentation. This work is already deployed in Google Chrome, benefitting millions of users, and was developed over a summer collaboration with three Ph.D. interns; it exemplifies how Research at Google is focused on rapidly bringing significant benefits to our users through groundbreaking technology and real-world products.
“Thialfi: A Client Notification Service for Internet-Scale Applications”, Atul Adya, Gregory Cooper, Daniel Myers, Michael Piatek,Proc. 23rd ACM Symposium on Operating Systems Principles (SOSP), 2011, pp. 129-142.
This paper describes a notification service that scales to hundreds of millions of users, provides sub-second latency in the common case, and guarantees delivery even in the presence of a wide variety of failures. The service has been deployed in several popular Google applications including Chrome, Google Plus, and Contacts.
Quick links
Other posts of interest
-
April 23, 2025
Introducing Mobility AI: Advancing urban transportation- Algorithms & Theory ·
- General Science ·
- Machine Intelligence
-
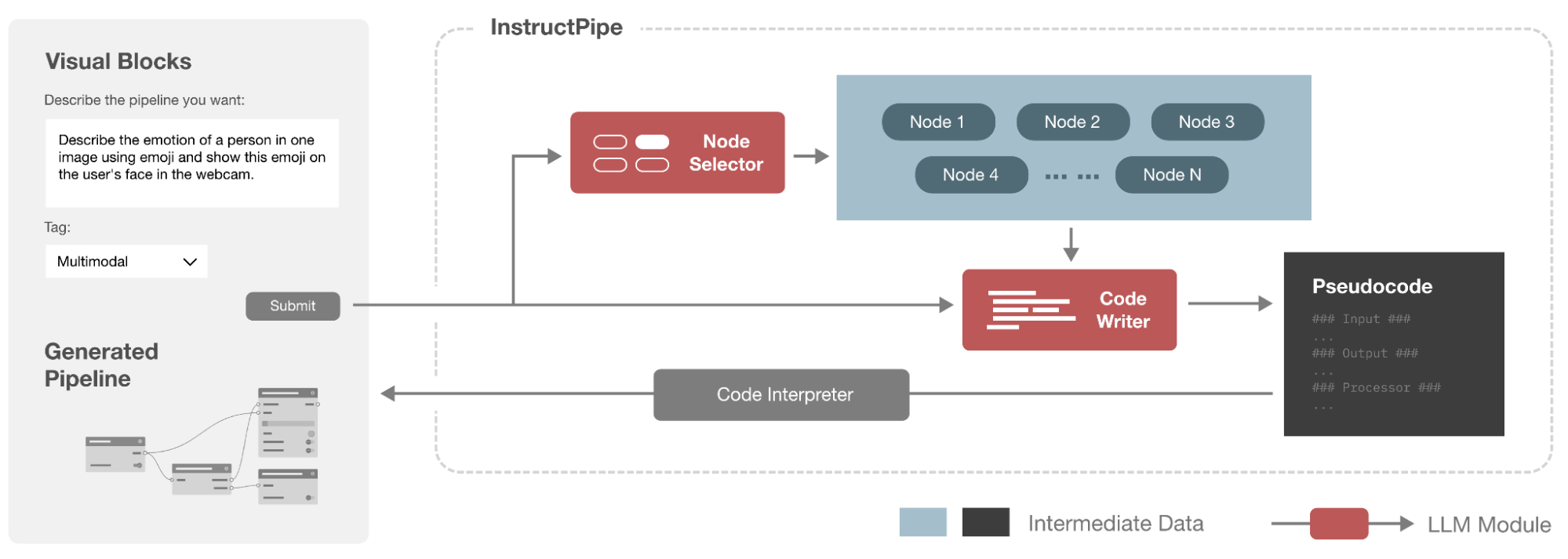
April 18, 2025
InstructPipe: Generating Visual Blocks pipelines with human instructions and LLMs- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
April 8, 2025
Geospatial Reasoning: Unlocking insights with generative AI and multiple foundation models- Climate & Sustainability ·
- Generative AI ·
- Machine Perception