11 Billion Clues in 800 Million Documents: A Web Research Corpus Annotated with Freebase Concepts
July 17, 2013
Posted by Dave Orr, Amar Subramanya, Evgeniy Gabrilovich, and Michael Ringgaard, Google Research
Quick links
“I assume that by knowing the truth you mean knowing things as they really are.”
- Plato
When you type in a search query -- perhaps Plato -- are you interested in the string of letters you typed? Or the concept or entity represented by that string? But knowing that the string represents something real and meaningful only gets you so far in computational linguistics or information retrieval -- you have to know what the string actually refers to. The Knowledge Graph and Freebase are databases of things, not strings, and references to them let you operate in the realm of concepts and entities rather than strings and n-grams.
We’ve previously released data to help with disambiguation and recently awarded $1.2M in research grants to work on related problems. Today we’re taking another step: releasing data consisting of nearly 800 million documents automatically annotated with over 11 billion references to Freebase entities.
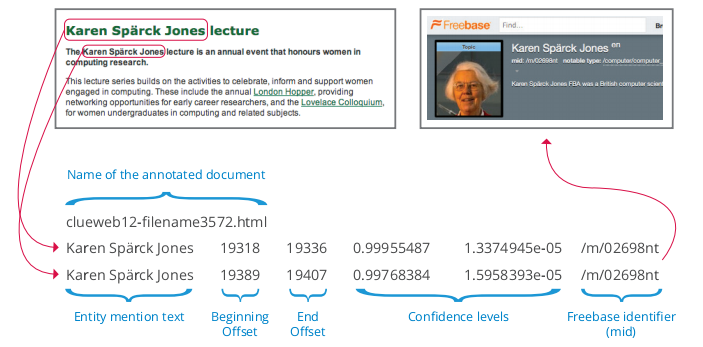
These Freebase Annotations of the ClueWeb Corpora (FACC) consist of ClueWeb09 FACC and ClueWeb12 FACC. 11 billion phrases that refer to concepts and entities in Freebase were automatically labeled with their unique identifiers (Freebase MID’s). For example:
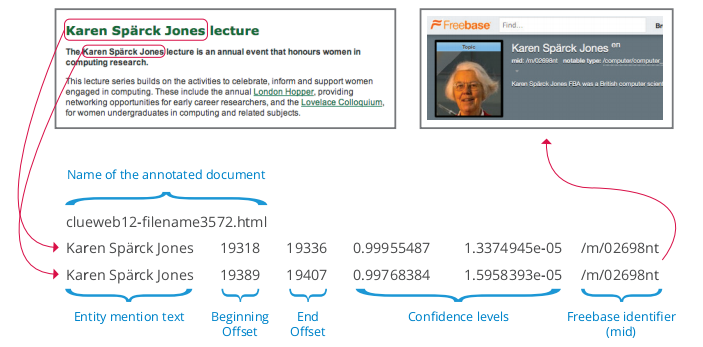
Since the annotation process was automatic, it likely made mistakes. We optimized for precision over recall, so the algorithm skipped a phrase if it wasn’t confident enough of the correct MID. If you prefer higher precision, we include confidence levels, so you can filter out lower confidence annotations that we did include.
Based on review of a sample of documents, we believe the precision is about 80-85%, and recall, which is inherently difficult to measure in situations like this, is in the range of 70-85%. Not every ClueWeb document is included in this corpus; documents in which we found no entities were excluded from the set. A document might be excluded because there were no entities to be found, because the entities in question weren’t in Freebase, or because none of the entities were resolved at a confidence level above the threshold.
The ClueWeb data is used in multiple TREC tracks. You may also be interested in our annotations of several TREC query sets, including those from the Million Query Track and Web Track.
If you would prefer a human-annotated set, you might want to look at the Wikilinks Corpus we released last year. Entities there were disambiguated by links to Wikipedia, inserted by the authors of the page, which is effectively a form of human annotation.
You can find more detail and download the data on the pages for the two sets: ClueWeb09 FACC and ClueWeb12 FACC. You can also subscribe to our data release mailing list to learn about releases as they happen.
Special thanks to Jamie Callan and Juan Caicedo Carvajal for their help throughout the annotation project.
-
Labels:
- Natural Language Processing
Quick links
Other posts of interest
-

July 29, 2025
Simulating large systems with Regression Language Models- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets ·
- Software Systems & Engineering
-

July 24, 2025
Synthetic and federated: Privacy-preserving domain adaptation with LLMs for mobile applications- Generative AI ·
- Natural Language Processing ·
- Product ·
- Responsible AI
-

June 3, 2025
Learning to clarify: Multi-turn conversations with Action-Based Contrastive Self-Training- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Natural Language Processing