Pulling Back the Curtain on Google’s Network Infrastructure
August 18, 2015
Posted by Amin Vahdat, Google Fellow
Quick links
Pursuing Google’s mission of organizing the world’s information to make it universally accessible and useful takes an enormous amount of computing and storage. In fact, it requires coordination across a warehouse-scale computer. Ten years ago, we realized that we could not purchase, at any price, a datacenter network that could meet the combination of our scale and speed requirements. So, we set out to build our own datacenter network hardware and software infrastructure. Today, at the ACM SIGCOMM conference, we are presenting a paper with the technical details on five generations of our in-house data center network architecture. This paper presents the technical details behind a talk we presented at Open Network Summit a few months ago.
From relatively humble beginnings, and after a misstep or two, we’ve built and deployed five generations of datacenter network infrastructure. Our latest-generation Jupiter network has improved capacity by more than 100x relative to our first generation network, delivering more than 1 petabit/sec of total bisection bandwidth. This means that each of 100,000 servers can communicate with one another in an arbitrary pattern at 10Gb/s.
Such network performance has been tremendously empowering for Google services. Engineers were liberated from optimizing their code for various levels of bandwidth hierarchy. For example, initially there were painful tradeoffs with careful data locality and placement of servers connected to the same top of rack switch versus correlated failures caused by a single switch failure. A high performance network supporting tens of thousands of servers with flat bandwidth also enabled individual applications to scale far beyond what was otherwise possible and enabled tight coupling among multiple federated services. Finally, we were able to substantially improve the efficiency of our compute and storage infrastructure. As quantified in this recent paper, scheduling a set of jobs over a single larger domain supports much higher utilization than scheduling the same jobs over multiple smaller domains.
Delivering such a network meant we had to solve some fundamental problems in networking. Ten years ago, networking was defined by the interaction of individual hardware elements, e.g., switches, speaking standardized protocols to dynamically learn what the network looks like. Based on this dynamically learned information, switches would set their forwarding behavior. While robust, these protocols targeted deployment environments with perhaps tens of switches communicating between between multiple organizations. Configuring and managing switches in such an environment was manual and error prone. Changes in network state would spread slowly through the network using a high-overhead broadcast protocol. Most challenging of all, the system could not scale to meet our needs.
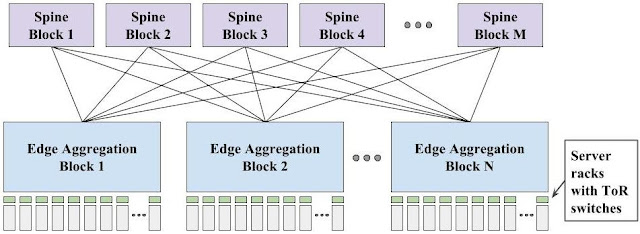
We adopted a set of principles to organize our networks that is now the primary driver for networking research and industrial innovation, Software Defined Networking (SDN). We observed that we could arrange emerging merchant switch silicon around a Clos topology to scale to the bandwidth requirements of a data center building. The topology of all five generations of our data center networks follow the blueprint below. Unfortunately, this meant that we would potentially require 10,000+ individual switching elements. Even if we could overcome the scalability challenges of existing network protocols, managing and configuring such a vast number of switching elements would be impossible.

- Our work on Bandwidth Enforcer shows how we can allocate wide area bandwidth among tens of thousands of individual applications based on centrally configured policy, substantially improving network utilization while simultaneously isolating services from one another.
- Condor addresses the challenges of designing data center network topologies. Network designers can specify constraints for data center networks; Condor efficiently generates candidate network designs that meet these constraints, and evaluates these candidates against a variety of target metrics.
- Congestion control in datacenter networks is challenging because of tiny buffers and very small round trip times. TIMELY shows how to manage datacenter bandwidth allocation while maintaining highly responsive and low latency network roundtrips in the data center.

Quick links
Other posts of interest
-

May 30, 2024
CodecLM: Aligning language models with tailored synthetic data- Conferences & Events ·
- Machine Intelligence ·
- Natural Language Processing
-
May 24, 2024
Google Research at Google I/O 2024- Conferences & Events ·
- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence ·
- Product ·
- Quantum ·
- Responsible AI
-

April 10, 2024
SOAR: New algorithms for even faster vector search with ScaNN- Algorithms & Theory ·
- Conferences & Events ·
- Data Mining & Modeling